When I wrote stljs, a library to read, write, and convert STL to PNG, one of the things I had to decide was how to calculate where the camera was located and where to point the camera. You want to be able to be able to show off the model at angles where you can see the most detail. How do you do that automatically for any sized object of any shape? I’ll show you how stljs does it.

Shows models rendered at the right angle
The first time I wrote an STL to PNG converter, it was just a simple script. In my haste to get it done, I picked a simple heuristic: Find the bounding box of the model, place the camera at the corner of the box times a multiplier and point the camera at the middle of the model.

When it’s a flat piece, the angle is wrong
Turns out this wasn’t a very good heuristic for all types of models. For flat parts, you’d see an edge-wise view of the part. And for long parts, you’d see a length-wise view of the part. In both instances, the most interesting part of the model is in the flatter part. And in addition, if the model was offset from the origin, it was often outside of the viewport.
And for a long time, Cubehero suffered in its display of models as a result. Many uploaded physibles with interesting models weren’t apparent as a result. I’m happy to say this is no longer the case. Stljs now employs a different heuristic to show models.
When you hold an object in your hands, you often hold the longest dimension perpendicular to your line of sight, since most of the surface area, and hence information is along that dimension. So let’s define some formulas to help us look perpendicular to the broadside of an object.
I decided to use a spherical coordinate system, because it’s easier to think about the camera swiveling around the object. We’ll start with figuring out the formulas for r, θ (theta), and φ (phi) and converting them to cartesian coordinates x, y, and z.
Let’s look at setting φ first. So if the part is flat, I want to be looking down at it. If it’s tall, I want to be looking horizontally at it. To tell how flat a part is, I decided to look at the ratio between its height (h) to its length (l) and width (w). When the ratio is high (the part is tall: h >> l + w), we want a φ ~= 0. When the ratio is low (the part is flat: h << l + w), we want a φ ~= 90. The range of the ratio is between 0 and ∞.
There’s only a few functions that would give us those characteristics, where there’s and inverse relationship between an input that is between 0 and ∞, and an output that is between 90 and 0. I chose the exponential decay function:
Phi = -π / 2 * e^(-h / (2 * (l + w)))
An exponential decay function fits the characteristics above, as well as the property of favoring an angled view of an object. If we pictured an object growing in height, but keeping a constant base, the camera would move quickly from a top-down view to an angled view, and then resist being completely horizontal as the object kept growing. I divided h by a factor of two to slow down this change.
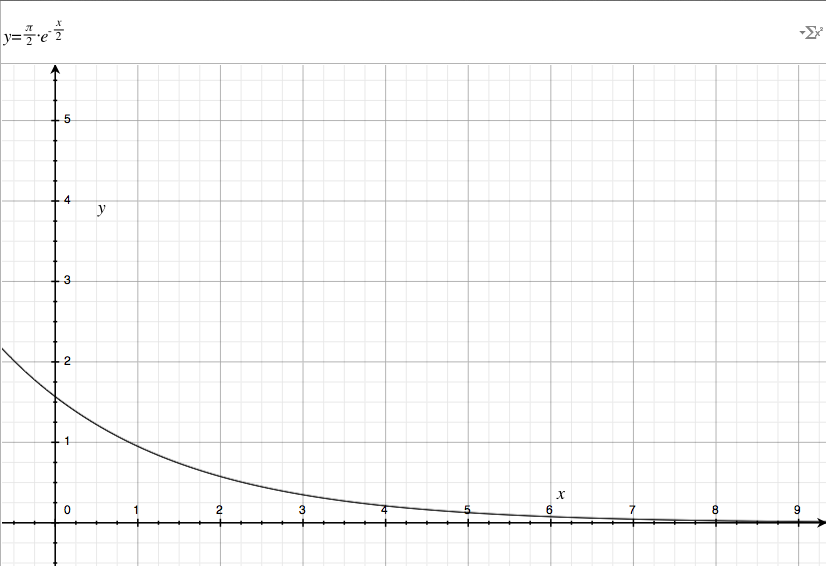
Decaying exponential
Similarly, for θ, we want the same sort of exponential decay function:
Theta = -π / 2 * e^(-l / w);
We only look at the ratio between length and width. By the same principal, we want the theta so we’re always looking at the broadside of an object.
Now radius was a little more difficult. Different size objects required a different distance to look at them. For any one dimension of the bounding box, I knew I wanted a view angle of 36 degrees. Therefore, I ended up with:
Radius = dimension / atan(π / 5)
But since I wanted to take into account every dimension, I calculated the radius for each dimension and took the max of them all:
Radius = max(w / atan(π / 5), l / atan(π / 5), h / atan(π / 5))
This makes sure we’re far enough away to see the entire object.
Sometimes, people save the STL object that’s not centered. So we have to adjust the object with offsets determined by the bounding box. We find the middle of the bounding box, but on the XY-Plane (hence we don’t add h / 2 to Z), since we don’t want a floating object.
X_offset = BoundingBox.Min.x + w / 2
Y_offset = BoundingBox.Min.y + l / 2
Z_offset = BoundingBox.Min.z
Now that we can calculate the spherical coordinates, we need to convert it to cartesian coordinates. That’s pretty standard textbook that you can look up on wikipedia or derive yourself. We add the offsets because we want the object centered in our view:
X = Radius * sin(Theta) * cos(Phi) + X_offset
Y = Radius * sin(Theta) * sin(Phi) + Y_offset
Z = Radius * cos(Theta) + Z_offset
Last thing, we need to determine where the camera looks. It should look at the middle of the floor bounding box, but 1/4 * h off the ground.
LookAt_X = X_offset
LookAt_Y = Y_offset
LookAt_Z = (BoundingBox.Max.z – BoundingBox.Min.z) / 4
And that’s it! If you have better suggestions than what I have here, please go to the stljs project page, and submit an issue.
Let me hear from you! Follow me on twitter, or ask me stuff on Google Plus.

Fascinating! Thanks for showing your work, I learned a lot from reading this.
Why add 1/4 of the height for the camera direction, as opposed to the center of the object?
The 1/4 height was just a heuristic that seemed to work well across a number of sizes. Because the camera location is elevated above an object, if we look at the center of the object, it tends to float.
How do you know you’re not looking at the “back” of something? To really maximize the amount of information you get from viewing an object from any given angle, I think you should count the number of surfaces visible (becomes complicated when you’re asking “how many” a non-flat surface is). Probably very hard to implement, both the counting and also the search for the optimal viewing point.
Technically, I don’t. It’s on the assumption that people orient their objects towards the ‘front’.
You’re on the right track, when looking at surfaces for information. However, the number of polygons/surfaces visible wouldn’t be a great metric, because you can have a bunch of co-planar polygons in the model. A better metric would be to calculate the entropy of the normals of the visible polygons.
The advantage of just using the length, width, and height ratios is that it’s fast to calculate, and gets you most of the way there.
Wow great post.. You did great job. Great information you have provided. Thanks for the post..!
I think this paper is about a closely related issue, so you might be able to get some ideas from it: “Finding the Best Viewpoints for Three-Dimensional Graph Drawings” (http://dl.acm.org/citation.cfm?id=728897)
Cool, thanks for the paper. I’ll look into it!